In the rapidly evolving landscape of networking technologies, one term gaining prominence is FCoE, or Fibre Channel over Ethernet. As businesses seek more efficient and cost-effective solutions, understanding the intricacies of FCoE becomes crucial. This article delves into the world of FCoE, exploring its definition, historical context, and key components to provide a comprehensive understanding of how it works.
What is FCoE (Fibre Channel over Ethernet)?
- In-Depth Definition
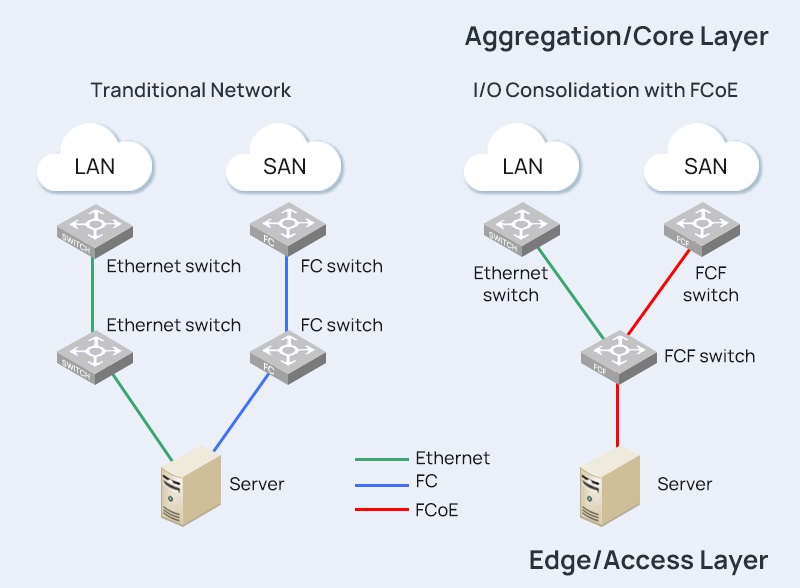
Fibre Channel over Ethernet, or FCoE, is a networking protocol that enables the convergence of traditional Fibre Channel storage networks with Ethernet-based data networks. This convergence is aimed at streamlining infrastructure, reducing costs, and enhancing overall network efficiency.
- Historical Context
The development of FCoE can be traced back to the need for a more unified and simplified networking environment. Traditionally, Fibre Channel and Ethernet operated as separate entities, each with its own set of protocols and infrastructure. FCoE emerged as a solution to bridge the gap between these two technologies, offering a more integrated and streamlined approach to data storage and transfer.
- Key Components
At its core, FCoE is a fusion of Fibre Channel and Ethernet technologies. The key components include Converged Network Adapters (CNAs), which allow for the transmission of both Fibre Channel and Ethernet traffic over a single network link. Additionally, FCoE employs a specific protocol stack that facilitates the encapsulation and transport of Fibre Channel frames within Ethernet frames.
How does Fibre Channel over Ethernet Work?
- Convergence of Fibre Channel and Ethernet
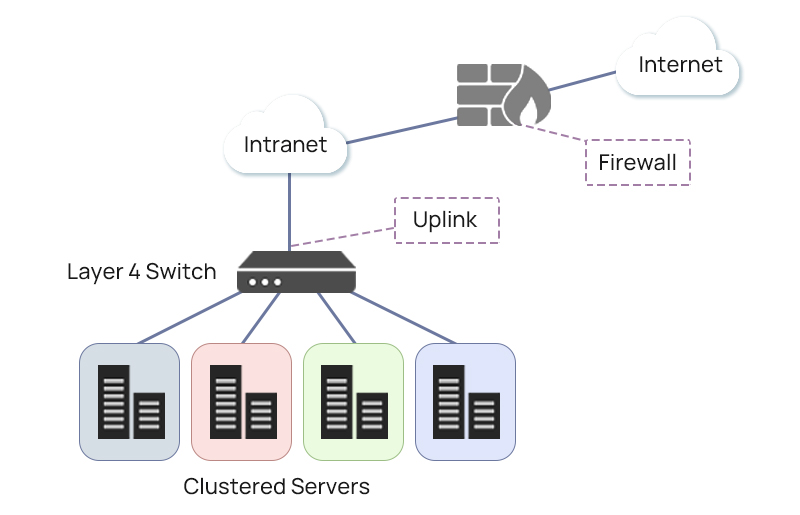
The fundamental principle behind FCoE is the convergence of Fibre Channel and Ethernet onto a shared network infrastructure. This convergence is achieved through the use of CNAs, specialized network interface cards that support both Fibre Channel and Ethernet protocols. By consolidating these technologies, FCoE eliminates the need for separate networks, reducing complexity and improving resource utilization.
- Protocol Stack Overview
FCoE utilizes a layered protocol stack to encapsulate Fibre Channel frames within Ethernet frames. This stack includes the Fibre Channel over Ethernet Initialization Protocol (FIP), which plays a crucial role in the discovery and initialization of FCoE-capable devices. The encapsulation process allows Fibre Channel traffic to traverse Ethernet networks seamlessly.
- FCoE vs. Traditional Fibre Channel
Comparing FCoE with traditional Fibre Channel reveals distinctive differences in their approaches to data networking. While traditional Fibre Channel relies on dedicated storage area networks (SANs), FCoE leverages Ethernet networks for both data and storage traffic. This fundamental shift impacts factors such as infrastructure complexity, cost, and overall network design.
” Also Check – IP SAN (IP Storage Area Network) vs. FCoE (Fibre Channel over Ethernet) | FS Community
What are the Advantages of Fibre Channel over Ethernet?
- Enhanced Network Efficiency
FCoE optimizes network efficiency by combining storage and data traffic on a single network. This consolidation reduces the overall network complexity and enhances the utilization of available resources, leading to improved performance and reduced bottlenecks.
- Cost Savings
One of the primary advantages of FCoE is the potential for cost savings. By converging Fibre Channel and Ethernet, organizations can eliminate the need for separate infrastructure and associated maintenance costs. This not only reduces capital expenses but also streamlines operational processes.
- Scalability and Flexibility
FCoE provides organizations with the scalability and flexibility needed in dynamic IT environments. The ability to seamlessly integrate new devices and technologies into the network allows for future expansion without the constraints of traditional networking approaches.
Conclusion
In conclusion, FCoE stands as a transformative technology that bridges the gap between Fibre Channel and Ethernet, offering enhanced efficiency, cost savings, and flexibility in network design. As businesses navigate the complexities of modern networking, understanding FCoE becomes essential for those seeking a streamlined and future-ready infrastructure.
Related Articles: Demystifying IP SAN: A Comprehensive Guide to Internet Protocol Storage Area Networks